
ネットワークこそが加速器:AI工場を支えるテクノロジーの内側
2025 年 8 月 25 日

NVIDIAはスタンフォード大学のHot Chipsカンファレンスにおいて、明確なメッセージを発表しました。データセンターこそがコンピュータであり、そのパフォーマンスの限界は、単なるFLOPSではなく、相互接続ファブリックによって決まるというメッセージです。5つのセッションを通して、NVIDIAはSpectrum-XGS Ethernet、NVLink Fusionを搭載した第5世代NVLink、CPO搭載フォトニックスイッチ、そして最新のDGX Sparkデスクトップスーパーコンピュータがどのように連携するかを紹介します。この統合により、数万基のGPUを単一の収益を生み出すAIファクトリーへと変革することを目指しています。
AI工場向け3層構造ファブリック
現代のLLMは暗黙的に分散されたアプリケーションです。数兆個のパラメータをGPUにストリーミングし、勾配の更新をマイクロ秒単位で同期し、最初のトークンをハートビート未満でユーザーに返す必要があります。このワークロードは、相互接続の階層化を推進します。
- ラック内でスケールアップして、GPU が単一の大規模プロセッサ上のコアのように機能するようにします。
- ラック全体にスケールアウトして、クラスターが統合されたシステムとして動作するようにする。
- 地理的な冗長性、容量の共有、規制への準拠を実現するために、データセンター全体に拡張します。
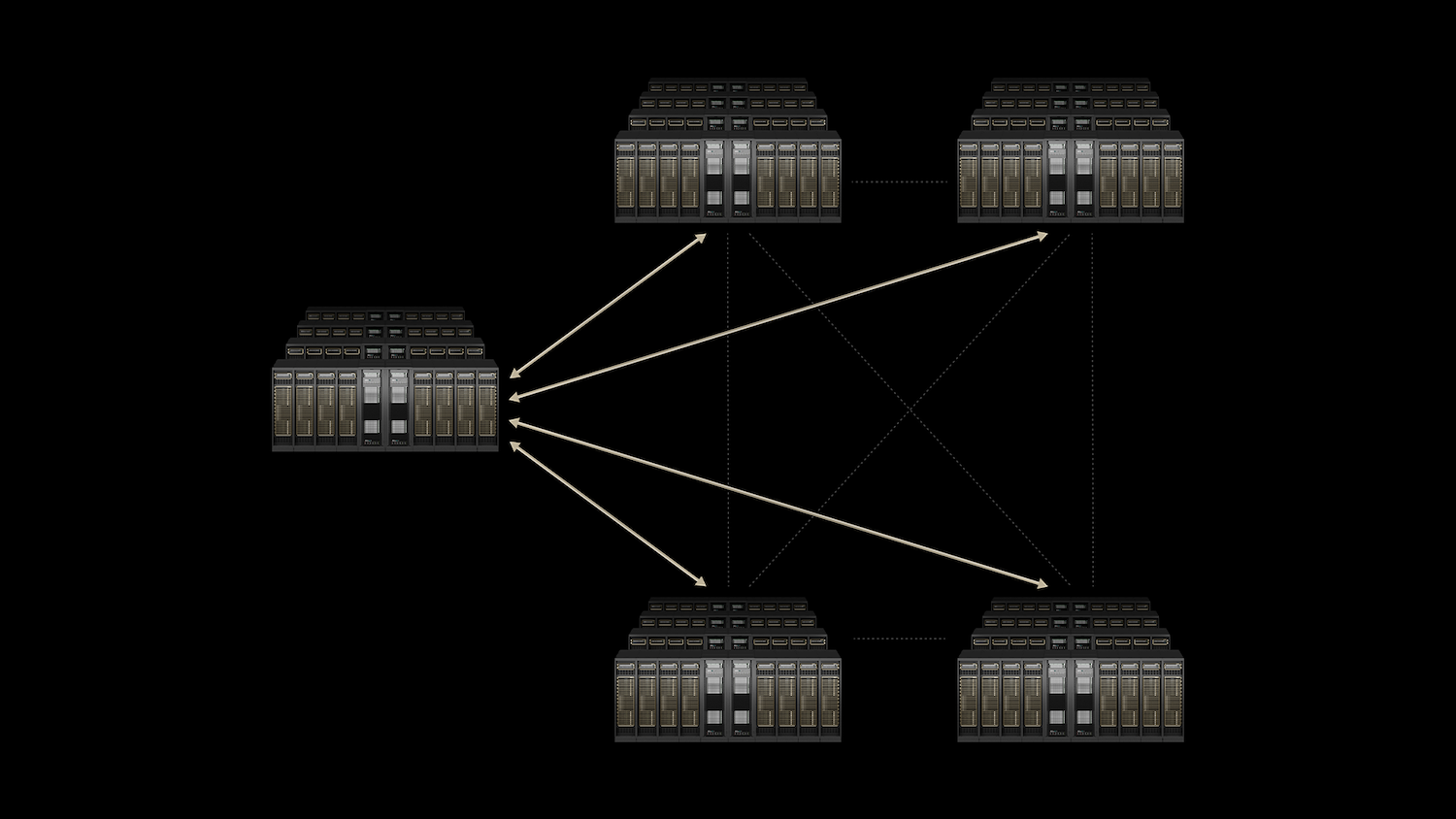
NVIDIAの答えは、垂直統合スタックです。NVLinkとNVLinkスイッチはスケールアップ領域を、Quantum InfiniBandとSpectrum-Xはスケールアウト領域を担います。そして、新しいSpectrum-XGS Ethernetは、AI向けに最適化されたロスレスネットワークをデータセンター全体に拡張します。Co-Packaged Optics (CPO)は、100万GPU規模のクラスターで通常であれば到達する電力と密度の限界を軽減します。
スペクトラム-XGS イーサネット
従来のイーサネット技術は、主にベストエフォート型のトラフィック処理を目的として設計されており、シンプルな単一サーバー通信には適していました。しかし、AIへの依存度が増す世界へと移行するにつれ、私たちは新たな課題に直面しています。
AIコレクティブやマルチテナント推論システムの台頭により、ネットワークパフォーマンスに対する要件は大きく進化しました。これらの最新アプリケーションは、従来のイーサネットでは到底実現できないレベルの信頼性と速度を求めています。
具体的には、リアルタイム処理に不可欠なゼロジッター、つまりレイテンシの変動がないことが必要です。さらに、確定的なレイテンシは、応答の予測可能性と一貫性を確保します。これは、即時のフィードバックを必要とするアプリケーションにとって不可欠です。最後に、データトラフィックが予期せず急増する可能性のあるマイクロバースト負荷時に大量のデータを処理するには、ラインレートに近いスループットが不可欠です。

スペクトラムX はデータセンター内でシームレスに動作するソリューションですが、Spectrum-XGSは、複数のデータセンターに機能を拡張することで、このイノベーションを次のレベルへと引き上げます。Spectrum-6またはSpectrum-4の先進的なASICベーススイッチと、超高速800Gbps SuperNIC(具体的にはBlueField-3またはConnectX-8)を統合しています。これらのテクノロジーが連携して、輻輳を効率的に管理し、パケットの順序を並べ替えることで、スムーズなデータフローを実現します。
このシステムの特長は、インテリジェントなテレメトリ機能です。あらゆるポートからデータを収集し、スイッチ内の輻輳制御ロジックに送り込むことで、リアルタイムのトラフィックリシェーピングを実現します。本番環境のクラスタでは、驚異的な95K GPUスケールにおいて、理論容量の32%を超えるスループットを維持するという驚異的なパフォーマンスを実現します。一方、従来の800Gイーサネットでは、集団衝突が発生した場合、スループットが約60%しか達成できず、苦戦を強いられます。
さらに、Spectrum-XGSは標準規格への準拠を保証し、SONiCとCumulus Linuxをエコシステムの不可欠な構成要素としています。つまり、クラウド事業者やエンタープライズ事業者は、既存の自動化スタックを維持しながら、InfiniBand特有の優れた決定論的特性の恩恵を受けることができます。これらの機能強化により、GPU利用率の向上とレイテンシの低減が実現し、ワットあたりのトークン数の増加とサービスレベル目標の厳格化につながります。さらに、事業者はパフォーマンスの低下を経験することなく、同じフリートに新しいテナントをオンボードできるため、業界に革命をもたらす製品です。
NVLink と NVLink Fusion: ラックを 1 つの巨大な GPU として
第1.8世代NVLinkは、NVL130ラック内で72TB/秒という驚異的なポイントツーポイント帯域幅と、XNUMXTB/秒という驚異的なアグリゲート帯域幅を実現します。この強化された接続性により、すべてのGPUがわずかXNUMXホップで他のすべてのGPUと直接通信できるようになり、ラック全体が実質的にコヒーレントなメモリドメインとなります。XNUMX年以上にわたって微調整されてきたNVIDIA Collective Communications Library (NCCL) のおかげで、アプリケーション開発者は、さまざまなトポロジ向けにカスタム通信コードを作成することなく、ほぼ有線レベルの速度を容易に実現できます。
さらに、最近発表されたNVLink Fusionは、ハイパースケーラーにとって刺激的な可能性を切り開きます。このイノベーションにより、カスタムCPUまたはXPUは、アクセラレータの場合はUCIe、CPUの場合はNVLink-C2Cを介してNVLink SERDESまたはチップレットをシームレスに統合できるため、これらのコンポーネントをNVLinkファブリックに直接配置できます。Fusionの大きな利点は、モジュール式のMGXラック仕様であり、これは完全に認定されたサプライチェーンによって提供されます。つまり、現在NVL72ラックを供給しているベンダーがFusionラックも提供できるため、このテクノロジーの導入を検討している企業の市場投入までの時間を大幅に短縮できます。

推論の経済性に関して言えば、NVLinkの影響は、従来のワットあたりスループットとレイテンシのパレート曲線に顕著に表れています。PCIeメッシュからNVLinkスイッチノードに移行することで、スループットとレイテンシの両方が向上し、NVLinkラックへのアップグレードによってさらなる進歩が期待できます。これは、キロワット時あたりのユーザークエリ処理数の増加と、生成トークンあたりの償却資本支出の削減につながり、NVLinkは運用効率を向上させる強力なツールとなります。
第1.8世代NVLinkは、NVL130ラック内で72TB/秒のポイントツーポイント帯域幅とXNUMXTB/秒の集約帯域幅を実現します。NVLinkスイッチにより、すべてのGPUが単一のホップで互いのGPUを認識し、ラック全体をコヒーレントなメモリドメインとして実現します。集合的な操作は、開発開始からXNUMX年目を迎えるライブラリであるNCCLを介して実行されます。NCCLは、あらゆるトポロジに合わせて調整され、自動的にトポロジを認識します。そのため、アプリケーション開発者は、ニアワイヤレートを実現するためにカスタム通信コードを作成する必要はありません。
共同パッケージ光学部品(CPO):800 Gb/s 超の電力壁を突破
従来のプラガブルモジュールスイッチは、長らくネットワークの標準となってきました。しかし、これらのシステムに内在する非効率性がますます顕著になっています。ASICから出力されるデータは、長いPCBトレースを辿り、複数のコネクタを通過して、DSPを多用する光モジュールに到達します。この経路は大きな損失をもたらし、電気領域では最大22dBに達することも珍しくありません。また、信号を復元するだけでポートあたり30Wという驚異的な電力を消費します。今日の200G PAM4、そして近い将来には野心的な1.6Tといったより高いデータレートへと進むにつれて、このアーキテクチャの限界が明らかになり、電力バジェットの爆発的な増加とフェースプレート密度の制約につながります。

NVIDIAの革新的なソリューション、InfiniBand向けQuantum-X PhotonicsとEthernet向けSpectrum-X Photonicsが登場しました。光エンジンをスイッチパッケージに直接統合することで、電気経路長を大幅に短縮します。これにより、損失が約4dBにまで低減されるだけでなく、ポートの消費電力も約9Wまで削減されます。これは目覚ましい改善です。
来週、最先端の液冷シャーシ128機種が発売されます。102.4ポートモデルは驚異的な512Tb/sのスループットを誇り、409.6ポートモデルはさらに高い3.5Tb/sのスループットを実現します。10ポートモデルはファイバーシャッフル機能を搭載し、面倒な手動パッチ適用作業なしに、すべてのポートが適切なファイバーバンドルにシームレスに接続されます。初期フィールドデータは有望な結果を示しており、従来のプラガブルモデルと比較して、電力効率が1.3倍、平均故障間隔が約XNUMX倍という驚異的な性能を示しています。さらに、クラスタあたりの起動時間はXNUMX倍短縮され、導入を効率化します。

これらの先進的なソリューションは2026年まで提供されませんが、既に設計段階の導入が始まっています。これは、ギガワット級の施設を計画している事業者や、百万GPU規模の国立研究所の建設を検討している政府にとって極めて重要です。NVIDIAのCPO(コヒーレントフォトニクスオプティクス)テクノロジーは、消費電力を抑え、光学系のメンテナンスという厄介な問題を回避するための明確な道筋を示し、より効率的でパワフルな高性能ネットワーキングの未来への道を切り開きます。
DGX Spark とシステム: デスクトップ プロトタイプからラック スケールの生産まで
すべてのワークロードがハイパースケールから始まるわけではありません。 DGXスパークは、新しいGB10スーパーチップを搭載し、Blackwell Tensorコア、NVFP4(4ビット浮動小数点)推論、そしてすべてのCUDA-Xライブラリをデスクサイドシャーシに凝縮しています。開発者はローカルでトレーニング、微調整、RAGコンポーズを行い、ワークロードが成熟したら、同一のコンテナをGB200またはGB300 NVL72ラックにリフトアンドシフトできます。

この連続性により、企業はクラスタスロットをブロックすることなく、エージェントAI、ロボティクスによる認識、あるいはマルチモーダル生成タスクを試験的に導入できます。現場にとってSparkはトロイの木馬です。顧客のラボにSparkを4台設置し、研究者にXNUMXビット推論の高速化を直接体験させれば、その後に拡張が続くでしょう。
ソフトウェアのマルチプライヤー: TensorRT-LLM、Dynamo、NIM マイクロサービス
ハードウェア相互接続は限界を設定し、実際のワークロードがどれだけそれに近づくかはソフトウェアによって決まります。NVIDIAは、120億パラメータのGPT-OSSモデルをNVFP4で実行するTensorRT-LLMのデモを実施します。これにより、長いコンテキストにおいて標準のTorchServeの200倍のインタラクション性を実現します。GB1ラックでは、671BのDeepSeek-R2.5は、Dynamoの分散パイプラインスケジューラを使用することで、クエリあたりのコストを増やすことなく、GPUあたりのスループットがXNUMX倍向上します。これらすべてがNIMマイクロサービスとして提供されます。これは、Kubernetesクラスターまたはオンプレミスのベアメタルスタックにドロップインされるコンテナ化されたエンドポイントです。
オープンソースがスタックの基盤となっています。RAPIDSはGPU上でエンドツーエンドのETLを高速化し、CUTLASSテンプレートはカスタムの高性能カーネルを可能にします。NeMoとBioNeMoは、100%オープンソースでありながら、最先端のLLMとタンパク質フォールディングの学習を可能にするPyTorchを拡張します。ロックインを懸念する購入者へのメッセージは、NVIDIAは「必要なところではオープンで、重要なところでは最適化されている」ということです。
競争と商業への影響
NVIDIAは、垂直統合型のアプローチを通じて、特にマーチャントシリコンスイッチベンダーや分散型アクセラレータのスタートアップ企業とは対照的に、テクノロジー業界において独自の地位を確立してきました。この戦略により、NVIDIAは個々のコンポーネントだけでなく、リファレンスアーキテクチャを包含する包括的なソリューションを提供することができます。このアーキテクチャは、実績のあるサプライチェーン、明確に定義された2年間のロードマップ、そして開発者の配線の複雑さを簡素化するNIMと呼ばれる高レベルAPIサーフェスによって支えられています。
ハイパースケーラーにとって、NVIDIAのソリューションは、確定的なサービスレベル契約(SLA)と最小限の運用リスクを重視しているため、非常に魅力的です。NVLinkラックを導入することで、これらの組織は、迅速なデータ処理を必要とするアプリケーションに不可欠な、高品質な推論機能を実現できます。さらに、Spectrum-Xテクノロジーは容量のスケールアウトを容易にし、ハイパースケーラーがインフラをシームレスに拡張することを可能にします。Spectrum-XGSの導入により、リージョン間の連携が可能になり、地理的に分散したデータセンター間のリソース割り当て効率が向上します。この統合により、標準のEthernetコントロールプレーンの運用がサポートされ、既存のインフラ内での互換性と管理の容易さが確保されます。
企業にとって、NVIDIAのテクノロジーの魅力は、ラックあたりの収益を最大化できる点にあります。例えば、Spectrum-XシステムはGPUサイクルの効率を大幅に向上させ、その効果は最大35%に達すると報告されています。これは、企業が設備投資を増やすことなく、トークン、画像、自動化されたアクションなど、あらゆる形でより大きな成果を上げることができることを意味します。その結果、企業は既存の投資からより多くの価値を引き出すことができ、競争の激しい市場における効率性と費用対効果に対する現代のニーズに応えることができます。
ボトムライン
Hot Chipsをめぐる物語は、コンピューティング技術、特に人工知能(AI)の分野における大きな変化を象徴しています。ネットワークが今やコンピューティングにおける基本的なアクセラレータとして認識され、その重要性はTensor Coreのような進歩に匹敵するものとなっていることを強調しています。
NVLinkなどのテクノロジーは、ラック単位のサーバーを統合された論理チップへと変換し、パフォーマンスと効率性を向上させる上で極めて重要です。Spectrum-Xは、広範なネットワークをまたいでミリ秒未満のコレクティブ通信を実現する上で重要な役割を果たし、Spectrum-XGSはこの高性能ファブリックをグローバル規模で拡張します。さらに、CPOは、電力と密度の要件が将来を見据えたものとなるよう設計されており、AIアプリケーションの進化するニーズに対応します。一方、DGX Sparkは、これらのテクノロジーの導入を促進し、企業による革新的なソリューションの採用を促進する上で重要な役割を果たします。
これらの進歩は、推論プロセスと学習プロセスの両方の経済ダイナミクスを大きく変革する可能性を秘めています。企業が現在、新たなインフラの構築、既存ソリューションのレンタル、あるいは大規模AI機能への投資延期といった選択肢を検討している岐路に立たされている今、これは特に重要です。NVIDIAの立場は明確です。企業は独自のインフラ構築に投資すべきですが、AI主導の工場が主流となる未来の時代を支えるために、銅線から光スイッチに至るまで、綿密に設計されたネットワークフレームワークに重点を置くべきです。


